סופם של הלינקים עבור SEO?
לפני כשבוע הכריזה גוגל על פטנט חדש לדירוג אתרים לפי מידת המהימנות שלהם כפי שהאלגוריתם של גוגל מעריך אותה. ברור לכל כי הפטנט כנראה לא מיושם עדיין בוודאי לא במלואו, אבל הוא בהחלט יכול לסמן בעתיד הלא רחוק את סופם של הלינקים או לפחות הפחתה משמעותית ביותר במידת חשיבותם.
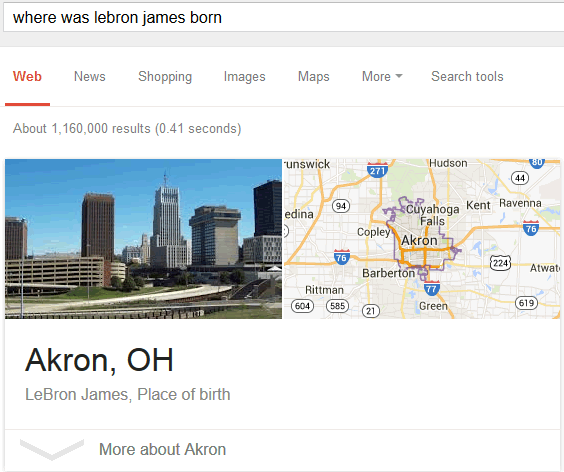
לאחר שנים של קיפאון נראה כי המנוע של גוגל (ובמידה רבה גם זה של בינג) מתעורר לחיים של חדשים, שלאו דווקא מבשרים טובות לבעלי האתרים. אותו מדד מהימנות שמופיע בפטנט של גוגל (Knowledge-Based Trust) קשור בעבותות של ברזל למנוע התשובות של גוגל – גרף המידע שבעצמו מתבסס על מחסן המידע (Knowledge Vault) של החברה, שנכון לכתיבת שורות אלה כולל 2.8 מיליארד עובדות שהאלגוריתם ליקט מרחבי הרשת (יש לשער שגם לסגירת השירות Freebase יש קשר לנושא).
המטרה של גוגל (ושוב, גם של בינג) היא ברורה: השארת הגולש בתוך המנוע במקום לשלוח אותו לאתרים חיצוניים ולחשוף אותו לכמה שיותר פרסומות ושירותים של גוגל על הדרך. המחיר: אתרים מתחילים לאבד טראפיק אורגני בכמויות גדולות (ויקיפדיה, למשל, איבדה למעלה מ-20% מהטראפיק האורגני מאז השקת גרף המידע). לא ברור עד כמה אסטרטגיית הסקרייפינג של גוגל יעילה לטווח הארוך, מצד אחד אתרים לא ינדבו מידע לגרף המידע אם זה לא יזכה אותם בטראפיק, אבל מצד שני הופעה בגרף המידע יכולה לספק לאתר את אותם סיגנלים של מהימנות שיבטיחו דירוגים גבוהים. סוג של מלכוד 22.
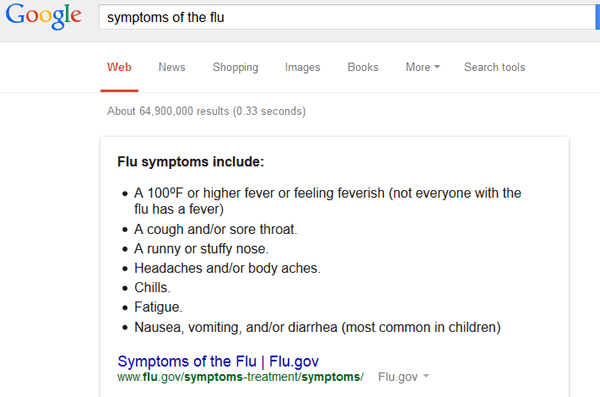
לצד גרף המידע, גוגל מרחיבה בשנים האחרונות באופן משמעותי גם את תיבות התשובות, שכעת כוללות לא רק ערכים השאובים מויקיפדיה או מקורות אחרים, אלא גם הוראות הפעלה, מידע שימושי, מידע רפואי ועוד אינספור דוגמאות שנותנות מענה לשאילתת החיפוש ישירות מתוך המנוע ומבלי צורך לצאת לאף אתר חיצוני.
השפעה לטווח ארוך על SEO ובכלל
למרות שהאלגוריתם עדיין לא יושם, אפשר כבר היום לראות דוגמאות למכביר כיצד אנשי SEO יכולים לתמרן את המידע שמופיע בגרף המידע של גוגל וכיצד המידע המוצג שם אינו תמיד מדויק. ראשית, מידע שנשאב מויקיפדיה הוא מידע שניתן לשינוי על ידי כל משתמש מורשה (וידוע כי הרבה משתמשים מורשים מוכרים את שירותי העריכה שלהם) ושנית, וזו הנקודה המשמעותית יותר, המידע באינטרנט הוא לא תמיד נכון ומדויק במאת האחוזים (בלשון המעטה). מאמר שפורסם לאחרונה ב-CNN לועג למנוע העובדות של גוגל ("מצאתי את זה באינטרנט, את זה לבטח אמיתי") ומציף שוב העובדה שמידע באינטרנט, בחלק מהמקרים, אינו יכול לשמש תחליף למקורות מהימנים יותר שעוברים עריכה קפדנית של אנשי מקצוע.
הצגת "עובדות מאומתות" בגרף המידע ובתיבות התשובות עלולה להנציח מידע שהוא שגוי בפוטנציה וגרוע מכך: להתעלם ממידע חדש עד שהאלגוריתם "יחליט" שהוא מספיק מהימן להיכנס למאגר המידע.
אז נכון לעכשיו ההשפעה של Knowledge-Based Trust מינורית מבחינת SEO, אבל יש לשער שהיא תגדל משמעותית בעתיד הקרוב. רוב אנשי ה-SEO עדיין זוכרים את ה- Author Rank הכושל, באמצעותו ניסתה גוגל לזהות מומחים בתחומם, בלתי אפשרי לדעת האם גם ל- Knowledge-Based Trust צפוי עתיד דומה, אבל אם לוקחים בחשבון עד כמה משולבים גרף המידע ומנוע התשובות בגוגל, התשובה היא כנראה שזה העתיד הבלתי נמנע. צרפו לכך את העובדה כי הן IBM, פייסבוק, מיקרוסופט וכנראה חברות רבות נוספות עובדות על בניית מאגרי מידע דומים, הרי שללינק כפקטור המשפיע ביותר על דירוגי האתרים צפוי עתיד לא מזהיר במיוחד, מה שמחייב אנשי SEO להתחיל להיערך לעתיד הזה כבר היום.
מה כן אפשר לעשות?
תוכן הוא אכן המלך, אבל לא עוד גיבובי מילים סתמיים לצרכי קידום, אלא תוכן אמתי, שימושי (לאו דווקא ארוך במיוחד) וכזה שיכול למצוא את מקומות בגרף המידע ובתיבת התשובות של גוגל. כתיבה עובדתית מלווה במקורות מידע מהימנים עד להפיכת האתר שלכם למקור מידע מהימן בפני עצמו.